Key takeaways
- Well-structured metadata and custom taxonomy transform DAM from an asset ‘repository’ into a governed system of record for enterprise content.
- A well-designed DAM taxonomy underpins content governance, automation, and AI-powered discovery across brands, regions, and channels.
- AI can accelerate tagging, enrichment, and search, but only when built on structured taxonomy and governed metadata.
- Forward-thinking enterprises are using DAM as a strategic content engine to scale content operations while reducing risk and manual effort.
- Platforms like Bynder combine configurable taxonomy, governance, and AI agents to operationalize metadata at enterprise scale.
Content has become one of the most valuable assets in a modern enterprise; powering every digital experience, marketing initiative, and brand interaction. But with the volume, velocity, and complexity involved, simply centralizing your digital assets in a DAM is no longer enough.
To scale content operations, protect brand integrity, and unlock the true value of AI in your organization, you need a structured foundation that governs how content is classified, accessed, and activated.
This is where metadata and custom taxonomy become foundational. Because, when designed correctly, they elevate a DAM from a storage solution into a system of record; a single source of truth that ensures that all content is brand-approved, searchable, compliant, and ready for activation across every channel, region, and market.
Platforms like Bynder are designed to support this shift; placing DAM at the center of an enterprise’s content ecosystem with configurable taxonomy, granular permissions, and AI-powered asset discovery already built in.
When this foundation is in place, organizations can directly connect content structure to productivity gains, reduced risk, and measurable business impact (an outcome explored in more depth within our guide, The ROI of DAM).
What is DAM taxonomy?
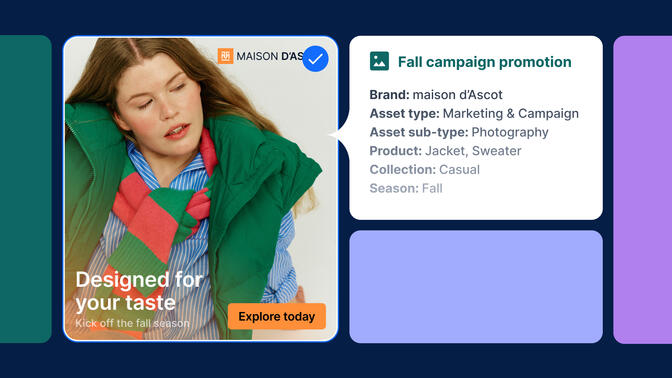
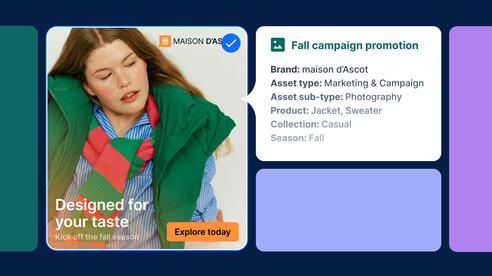
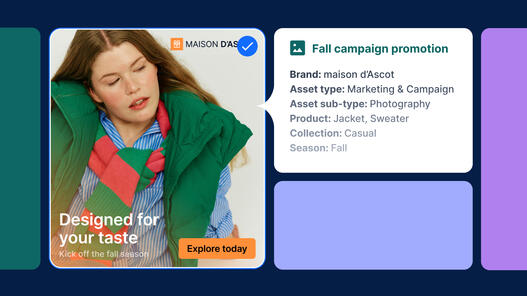
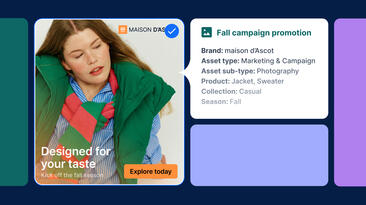
DAM taxonomy is the structured classification framework that defines how digital assets are organized, tagged, and retrieved within a DAM platform. It places assets within business context, such as:
- Brand
- Region
- Campaign
- Usage rights
- Audience
It means that teams can locate files more easily and use them with complete confidence.
Unlike static folder structures, taxonomy in an enterprise DAM is dynamic and configurable. Assets can exist in multiple logical categories at the same time, supporting the use of advanced filtering, automation, and role-based permissions.
And when paired with metadata and pre-defined terms, taxonomy becomes the backbone of a DAM operating as a system of record; rather than a passive repository for digital assets.
In practice, metadata spans multiple dimensions, from descriptive and technical details to rights, and preservation. This ensures that assets remain searchable, compliant, and usable throughout their lifecycle.
Taxonomy vs naming conventions: why both still matter
As AI becomes more deeply embedded in DAM platforms, it’s easy to assume that asset naming conventions are becoming irrelevant. In reality, taxonomy and naming conventions serve different, and complementary, purposes:
- Taxonomy is the map that tells your teams where content lives and how it connects to the wider business.
- Naming conventions are the ‘labels’ on the ‘books’ (but in this context, digital assets), that give each one a clear, human-readable identity.
It means that naming conventions remain critical because assets rarely stay confined to the DAM. For example, when an asset is shared via email, a design tool, a CMS, or a partner platform, a consistent naming structure allows assets to remain identifiable and usable wherever they are shared, received or accessed.
At the same time, naming conventions provide valuable signals that help AI interpret an asset’s purpose, format, and relevance.
Together, taxonomy and naming conventions create clarity for humans and AI, both inside and outside the DAM.
What are the different types of DAM taxonomy?
There is no single taxonomy model that works for every enterprise, so the right approach depends on factors like scale, content diversity, and how your users actually search for assets.
Flat taxonomy: This taxonomy type relies on a limited number of high-level categories, with rich metadata used for filtering. Its model can work well for organizations with fewer brands or asset types, and it’s simpler to maintain.
Hierarchical or nested taxonomy: This introduces parent-child relationships between categories, allowing users to drill down through structured layers, and it’s for that reason that it’s often the best model for large enterprises that need to manage multiple brands, product lines, or regions.
Most enterprise DAMs use a hybrid approach that combines hierarchical taxonomy with rich metadata. While the hierarchy provides a logical structure, the rich metadata allows the same asset to appear in multiple contexts without relying solely on rigid, folder-like pathways.
Common challenges in DAM taxonomy design
Even the most well-intentioned taxonomy projects can fail without the right foundations. Common challenges include:
- Siloed teams: Different departments using different terminology, which undermines consistency and searchability.
- Inconsistent naming: A lack of naming control means that similar assets are tagged in multiple ways.
- Unstructured metadata: Free-text fields with no pre-set standards limit automation and AI effectiveness.
- Evolving content types and channels: New formats and markets can quickly outgrow a rigid taxonomy structure.
- Inherent complexity in rights and localization: Usage restriction, embargoes, and regional variations need precise governance to avoid brand, reputational, and legal or regulatory risk.
Overcoming these obstacles requires both the right technical structure and organizational alignment.
Best practices for designing a future-ready DAM taxonomy
Design around user behavior
An effective taxonomy reflects how users actually search for assets, so taking time to analyze search logs, run internal workshops, and test category models help ensure that the taxonomy you land on aligns with real-life workflows.
Define guiding principles and pre-defined terms
Pre-defined terms reduce ambiguity, while clear principles for aspects like hierarchy ‘depth’ and category logic help to keep taxonomy scalable as your organization’s content ecosystem evolves.
Enforce consistent naming conventions
Defining mandatory elements such as asset type, campaign, and version ensures there’s clarity beyond the DAM while also improving both AI indexing and automation performance.
Use AI-powered tagging and metadata enrichment
Modern DAM platforms use context-aware AI to detect objects, text, faces, and scenes within assets. These enrichment capabilities dramatically reduce manual effort and improve consistency, but only when built on a structured taxonomy and governed metadata.
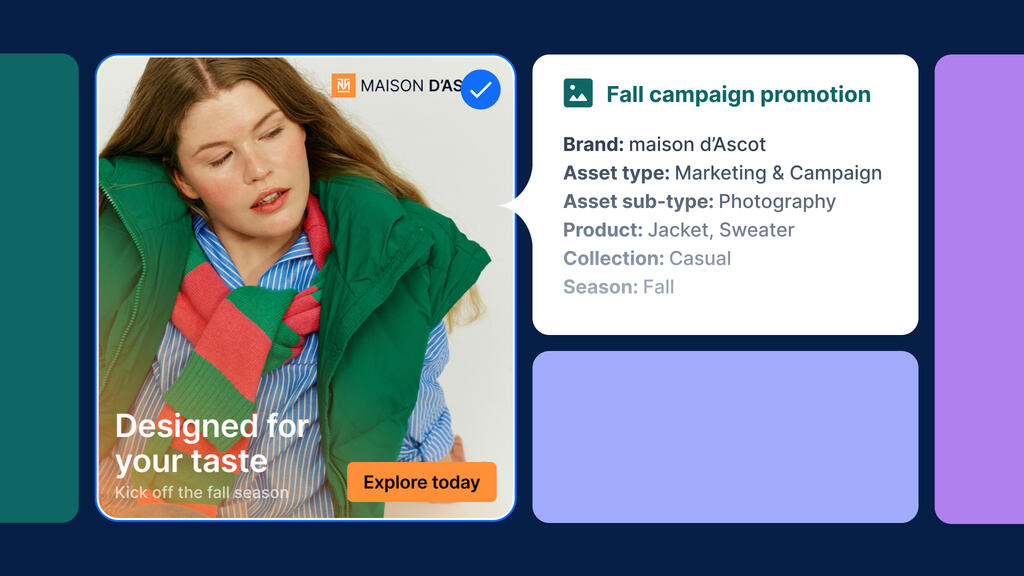
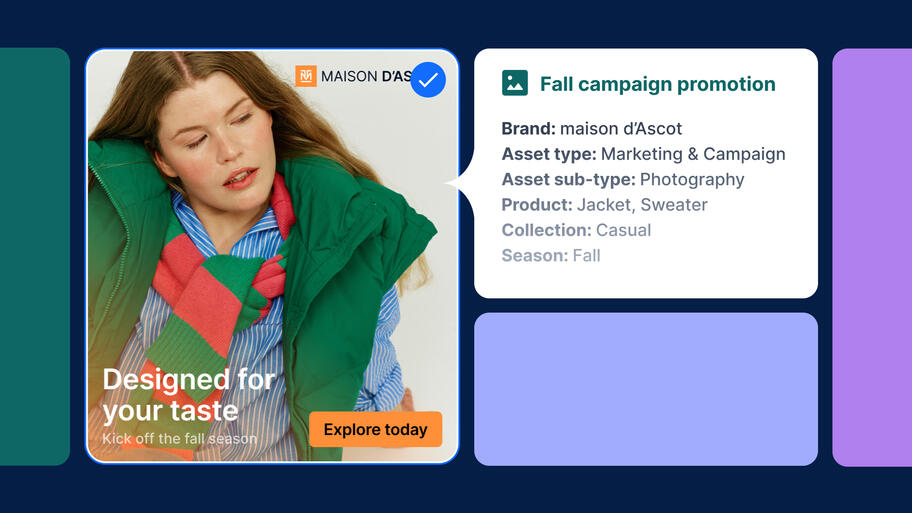
Bynder extends this further with AI Agents that can operationalize metadata at scale. Its Enrichment Agent can automatically identify content being uploaded to the DAM and generate and apply metadata such as alt text and tags across images, videos, and documents, while remaining aligned with controlled vocabularies and governance rules set in the DAM.
Embed governance as an ongoing discipline
When implemented as part of a strategically deployed DAM, governance turns your taxonomy into a living, breathing system in the DAM.
In the Bynder DAM, governance is enforced through configurable metadata schemes, controlled vocabularies, and role-based permissions. This ensures that assets are consistently structured, compliant, and ready for activation without relying on manual ‘policing’.
Related: Download our guide: Taxonomy and metadata best practice for DAM
DAM taxonomy in practice
In enterprise environments, the DAM taxonomy enables users to filter assets across multiple dimensions at once, for example: asset type, brand, product group, language, usage rights.
This means that teams can quickly locate the content that is relevant and approved for their intended end use.
Take San Diego-based flooring and building materials brand, CALI, for instance.
Before adopting Bynder DAM, CALI struggled with scattered files across multiple systems (Flickr, Google Drive, CALI’s website, and ERP), making it difficult to find the right content and maintain visibility over who had access to what.
After implementing Bynder DAM, CALI established a system of record for all of its digital assets.
With robust taxonomy, meta property configuration, and search capabilities, users across CALI can now find, tag, and reuse assets quickly. This dramatically reduced the number of media requests received by the marketing team; allowing them more time to focus on other, more valuable tasks.
Bynder's robust taxonomy, metadata, and search capabilities free me up from having to find assets for people. I no longer get requests for visual assets because everything can be easily found in the DAM.Walker Hicks
Art Director at CALI
This real-world example demonstrates how taxonomy and metadata make DAM not just more structured, but more usable.
The future of metadata and taxonomy in enterprise DAM
Forward-thinking enterprises are reevaluating how DAM must support governance, automation, and AI at scale.
The future of DAM taxonomy isn’t about adding more tags; it’s about enabling smarter systems that drive measurable outcomes.
In short: DAM is no longer an asset repository; it’s evolved into a strategic content engine. AI-powered search, natural language queries, similarity search, and automated enrichment are changing how teams interact with content assets.
Users no longer need to know exact terminology to find what they need; they can describe intent, and the DAM surfaces relevant assets in response. This is only possible because structured taxonomy and governed metadata provide the semantic context that AI uses to interpret and match intent accurately.
Increasingly, enterprises are using agentic AI to automate parts of the content supply chain itself. Within Bynder, AI Agents can support enrichment, transformation, and governance workflows. For example, applying metadata consistently at scale or detecting outdated or non-compliant assets.
Crucially, these assets rely on the DAM’s taxonomy and metadata model as their source of truth. Without that structured foundation, agentic AI cannot operate reliably or at enterprise scale.
At the same time, human oversight remains essential. The most successful DAM strategies combine AI-driven enrichment with governed metadata, controlled vocabularies, and clear ownership. This balance allows organizations to scale automation while maintaining trust, compliance, and brand integrity.
Implementing DAM taxonomy best practices for your enterprise
DAM taxonomy best practice is not about creating a perfect structure on day one; it’s about establishing a governed foundation that can evolve as your content ecosystem grows in complexity, volume, and velocity.
Enterprises that succeed treat taxonomy as part of a strategically deployed DAM; one that acts as a system of record for content, connects upstream and downstream tools, and enables automation and AI without compromising control.
This requires configurable taxonomy models, embedded governance, and AI capabilities that work with structure rather than around it.
Bynder supports this approach by combining enterprise-grade DAM, flexible metadata and taxonomy configuration, and AI Agents that help teams scale enrichment, governance, and activation workflows.
The result is a content foundation that reduces manual effort, minimizes risk, and enables faster, more confident content reuse across markets and channels.
Request a 1:1 demo and learn how Bynder DAM helps enterprises govern, enrich, and activate content at scale, turning taxonomy into a strategic capability rather than an operational burden.